
Liquid AI, a new MIT spinoff, wants to build an entirely new type of AI | TechCrunch
5 min read
[ad_1]
An MIT spinoff co-founded by robotics luminary Daniela Rus aims to build general-purpose AI systems powered by a relatively new type of AI model called a liquid neural network.
The spinoff, aptly named Liquid AI, emerged from stealth this morning and announced that it has raised $37.5 million — substantial for a two-stage seed round — from VCs and organizations including OSS Capital, PagsGroup, WordPress parent company Automattic, Samsung Next, Bold Capital Partners and ISAI Cap Venture, as well as angel investors like GitHub co-founder Tom Preston Werner, Shopify co-founder Tobias Lütke and Red Hat co-founder Bob Young.
The tranche values Liquid AI at $303 million post-money.
Joining Rus on the founding Liquid AI team are Ramin Hasani (CEO), Mathias Lechner (CTO) and Alexander Amini (chief scientific officer). Hasani was previously the principal AI scientist at Vanguard before joining MIT as a postdoctoral associate and research associate, while Lechner and Amini are longtime MIT researchers, having contributed — along with Hasani and Rus — to the invention of liquid neural networks.
What are liquid neural networks, you might be wondering? My colleague Brian Heater has written about them extensively, and I strongly encourage you to read his recent interview with Rus on the topic. But I’ll do my best to cover the salient points.
A research paper titled “Liquid Time-constant Networks,” published at the tail end of 2020 by Hasani, Rus, Lechner, Amini and others, put liquid neural networks on the map following several years of fits and starts; liquid neural networks as a concept have been around since 2018.
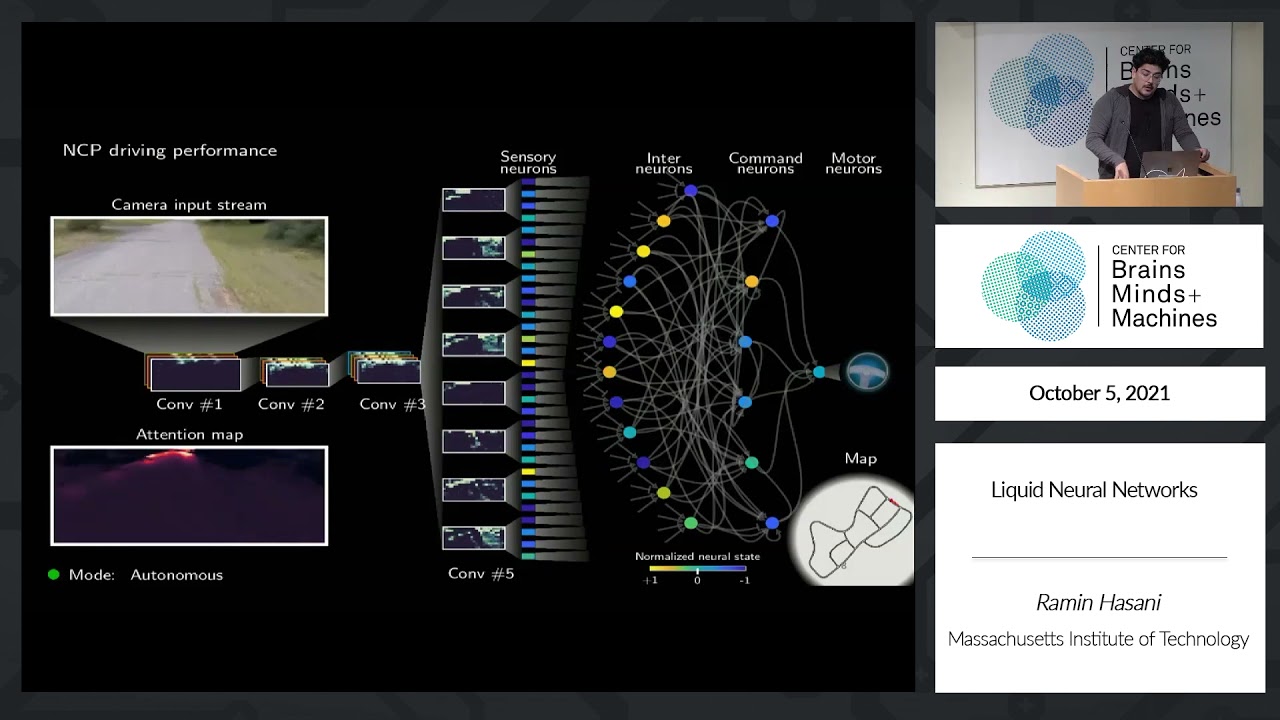
Image Credits: MIT CSAIL
“The idea was invented originally at the Vienna University of Technology, Austria at professor Radu Grosu’s lab, where I completed my Ph.D. and Mathias Lechner his master’s degree,” Hasani told TechCrunch in an email interview. “The work then got refined and scaled at Rus’ lab at MIT CSAIL, where Amini and Rus joined Mathias and I.”
Liquid neural networks consist of “neurons” governed by equations that predict each individual neuron’s behavior over time, like most other modern model architectures. The “liquid” bit in the term “liquid neural networks” refers to the architecture’s flexibility; inspired by the “brains” of roundworms, not only are liquid neural networks much smaller than traditional AI models, but they require far less compute power to run.
It’s helpful, I think, to compare a liquid neural network to a typical generative AI model.
GPT-3, the predecessor to OpenAI’s text-generating, image-analyzing model GPT-4, contains about 175 billion parameters and ~50,000 neurons — “parameters” being the parts of the model learned from training data that essentially define the skill of the model on a problem (in GPT-3’s case generating text). By contrast, a liquid neural network trained for a task like navigating a drone through an outdoor environment can contain as few as 20,000 parameters and fewer than 20 neurons.
Generally speaking, fewer parameters and neurons translates to less compute needed to train and run the model, an attractive prospect at a time when AI compute capacity is at a premium. A liquid neural network designed to drive a car autonomously could in theory run on a Raspberry Pi, to give a concrete example.
Liquid neural networks’ small size and straightforward architecture afford the added advantage of interpretability. It makes intuitive sense — figuring out the function of every neuron inside a liquid neural network is a more manageable task than figuring out the function of the 50,000-or-so neurons in GPT-3 (although there have been reasonably successful efforts to do this).
Now, few-parameter models capable of autonomous driving, text generation and more already exist. But low overhead isn’t the only thing that liquid neural networks have going for them.
Liquid neural networks’ other appealing — and arguably more unique — feature is their ability to adapt their parameters for “success” over time. The networks consider sequences of data as opposed to the isolated slices or snapshots most models process and adjust the exchange of signals between their neurons dynamically. These qualities let liquid neural networks deal with shifts in their surroundings and circumstances even if they weren’t trained to anticipate these shifts, such as changing weather conditions in the context of self-driving.
In tests, liquid neural networks have edged out other state-of-the-art algorithms in predicting future values in datasets spanning atmospheric chemistry to car traffic. But more impressive — at least to this writer — is what they’ve achieved in autonomous navigation.
Earlier this year, Rus and the rest of Liquid AI’s team trained a liquid neural network on data collected by a professional human drone pilot. They then deployed the algorithm on a fleet of quadrotors, which underwent long-distance, target-tracking and other tests in a range of outdoor environments, including a forest and dense city neighborhood.
According to the team, the liquid neural network beat other models trained for navigation — managing to make decisions that led the drones to targets in previously unexplored spaces even in the presence of noise and other challenges. Moreover, the liquid neural network was the only model that could reliably generalize to scenarios it hadn’t seen without any fine-tuning.
Drone search and rescue, wildlife monitoring and delivery are among the more obvious applications of liquid neural networks. But Rus and the rest of the Liquid AI team assert that the architecture is suited to analyzing any phenomena that fluctuate over time, including electric power grids, medical readouts, financial transactions and severe weather patterns. As long as there’s a dataset with sequential data, like video, liquid neural networks can train on it.
So what exactly does Liquid AI the startup hope to achieve with this powerful new(ish) architecture? Plain and simple, commercialization.
“[We compete] with foundation model companies building GPTs,” Hasani said — not naming names but not-so-subtly gesturing toward OpenAI and its many rivals (e.g. Anthropic, Stability AI, Cohere, AI21 Labs, etc.) in the generative AI space. “[The seed funding] will allow us to build the best-in-class new Liquid foundation models beyond GPTs.”
One presumes work will continue on the liquid neural network architecture, as well. Just in 2022, Rus’ lab devised a way to scale liquid neural networks far beyond what was once computationally practical; other breakthroughs could be lurking on the horizon with any luck.
Beyond designing and training new models, Liquid AI plans to provide on-premises and private AI infrastructure for customers and a platform that’ll enable these customers to build their own models for whatever use cases they conjure up — subject to Liquid AI’s terms, of course.
“Accountability and safety of large AI models is of paramount importance,” Hasani added. “Liquid AI offers more capital efficient, reliable, explainable and capable machine learning models for both domain-specific and generative AI applications.”
Liquid AI, which has a presence in Palo Alto in addition to Boston, has a 12-person team. Hasani expects that number to grow to 20 by early next year.
[ad_2]
Source link



